Shownotes R from Scratch Ep2
1] Variables – What is a variable?
2] Vectors – Vectors in R Tutorial
3] Projects (.RPROJ files) Using Projects in R
5] Code versus RStudio – Writing code in RStudio
Shownotes R from Scratch Ep2
1] Variables – What is a variable?
2] Vectors – Vectors in R Tutorial
3] Projects (.RPROJ files) Using Projects in R
5] Code versus RStudio – Writing code in RStudio
Shownotes R from scratch ep1
I’m Richard Treves, @Trevesy on twitter
Part 2:
Other R podcasts mentioned: Credibly Curious, The R-Podcast
Part 3:
RStudio download, RStudio tutorials
Part 4:
Wikipedia on R statistical features, Free R textbook
This post is a repost from the Open University team blog
In the Open University, we have developed a suite of LA (Learning Analytics) visualisations called ‘Action for Analytics’ (A4A: slides from a presentation giving more detail) designed to help those responsible for producing modules to see the effects of their designs. For example, it’s possible to track just how much use videos we produce for the module get watched and therefore see whether doing more would be a good investment.
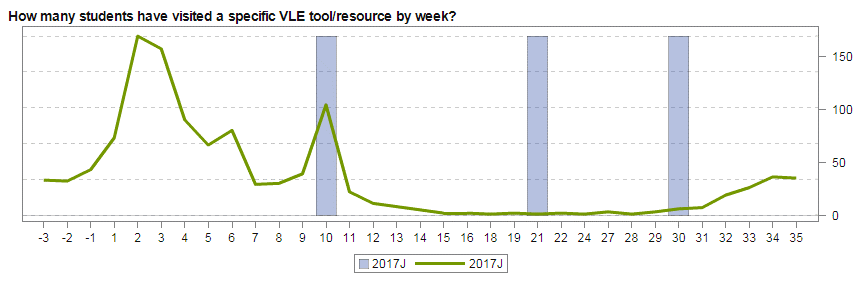
This has been very successful with our colleagues outside the Learning Design team (mostly academics) being able to track what is going on with their modules real time and also see the effects of changes as they are bought in.
However, the tool is limited to a set of ‘baked in’ dashboards so its not possible to split the above data into students who ended up failing the module from those who passed and compare the two graphs. This could give useful insight into the value of individual parts of a module and also if students are accessing it or not.
Drilling down into the data: A4A isn’t the only route to exploring statistics about students on modules. There are a number of databases underlying the visualisations and these can be accessed directly by specialist staff. Using our access rights, we have been experimenting with producing bespoke visualisations not in the current suite that we think could help those writing and designing modules. These are currently prototypes but show some promise:
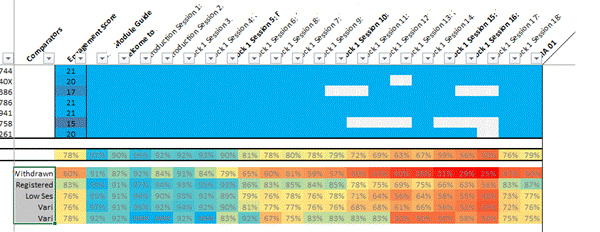
 In this visualisation, individual students are shown one per row at the top. If they have accessed any element of the course (one section per column) the corresponding cell is blue. If they have never accessed it, it’s shown white. At the bottom, students are grouped (e.g. ‘withdrawers’ and ‘registered’ – not withdrawn) and cells are now coloured with hot colours showing low usage and cool colours showing high usage.
In this visualisation, individual students are shown one per row at the top. If they have accessed any element of the course (one section per column) the corresponding cell is blue. If they have never accessed it, it’s shown white. At the bottom, students are grouped (e.g. ‘withdrawers’ and ‘registered’ – not withdrawn) and cells are now coloured with hot colours showing low usage and cool colours showing high usage.
Example Interpretation: As an example of its use, the last column is the block assignment. It can clearly be seen that section 18 (column 2nd from right, expanded up left) is attracting a high percentage of students visiting it at least once. Section 17 (3rd from right) is attracting considerably lower numbers of students, especially amongst withdrawers. This is a factor of inclusion of section 18 in the assignment, whereas 17 is not and, as a result, students are choosing to skip it. From a design point of view, should it be included at all?
More granularity: In our work investigating this graphic, we think it will become even more useful when there are improvements in the granularity, at present we can only see that students have accessed a whole section. For example, it will be much more useful to see how far they got within a section itself – did they give up half way through? Improvements in the learning analytics the VLE records should help with this.
Next Steps: This is a work in progress, already we are making the patchwork quilt visualisation more sophisticated and have plans for other experiments.
In my elearning career I have seen two ed technologies appear that have transformed learning* in my particular areas of interest (web based video and interactive web maps). On Friday, I saw a third: True AI marking via the Gallito tool which was presented by some colleagues from UNED, a Spanish university.
How it works: If you set up an open self assessment question in a course, you can define what the student should answer in terms of topics they should cover. This is then fed into a model which is transferred into an algorithm. Any answer the students give is analysed by the algorithm, it breaks down the text into grammar and then compares this to the answer it has. It gives the students a graph showing how they scored against various criteria. I had lots of questions for the presenters about how this actually works technically, unfortunately the programmers weren’t there to help their education colleagues so I didn’t get very far in understanding it. What they did make clear was that this isn’t a ‘black box’, they haven’t fed in a load of answers to the same questions with a tutors marks and used that to train a marking tool, the algorithm is designed from the ground up.
Testing it: The presenters then went on to show various ways they’ve tested this. UNED (the parent university) is a distance learning university in Spain that is publically funded, they put the algorithm to work assessing students formative work on a business course. Students could try a self assessment question and get immediate feedback: a mark and a graphical representation of where they’re answer was good or bad with respect to the marking criteria was given. Students liked the feedback and were prepared to answer the same question multiple times in order to improve their marks and to develop their understanding. UNED also used the tool to mark pre-exisiting assignments, they found that the tool marked close to the average of a group of makers who also marked the assignments. The human markers on the module varied between them, the tool was marking higher than the hard markers and lower than high markers (on average).
Applications: My description above has been fairly sketchy because it was a quick presentation. However, I believe that they’ve achieved a tool that can semantically break down a student answer and give pretty reasonable feedback. What is immediately obvious is that this is fantastic for formative marking: students building up to an assignment can practice their writing over and over before they attempt the actual assignment without having to involve a tutor at all. That could be a game changer for MOOCs who currently have to rely on multiple choice questions that are poor tools to test high level understanding.
Of course if Gallito does do what is claimed for it, it could also be used to mark students assignments. This area is much more contensious with lots of potential issues brewing. I suspect it will affect this area at some point in the future, just not for now.
Trialling it at the Open University: Along with a colleague, I’m very interested in seeing what the tool can do close up so we’re pushing to get a programme together to investigate it. Our colleagues at UNED are keen we do this.
The rise and rise of AI: I’ve read in the news about AI taking over all kinds of work. I didn’t think it would appear in teaching for a long while, years or even decades. However, it seems its here already. Is this is a disruptive technology that utterly changes education as we know it? I just don’t know. However, I am sure that if the tool proves itself it will be very significant.
*IMHO of course, you may have a different list.
So a think tank has been considering how to ‘Reboot learning for the digital age’. It came up with some recommendations:
My new employer, the Open University (UK) is doing all of these (and I have responsibility, along with my new team colleagues, for promoting 1 to 4).
I wonder how many other HEIs can say the same?
This post was originally posted on the closed ALT members list, it seemed to generate interest so I’ve reproduced it here.
The power of little data
Most of what I’ve come across in terms of Learning Analytics is thinking in terms of big data, an example problem: We’re tracking our 300 first years, given the hundreds of measures we have on the VLE and hundreds of thousands of data points, can we produce an algorithm that uses that big data to identify those in danger of dropping out and how should we best intervene to support them. Fine, a worthy project.
However, it isn’t the only way of tackling the problem. Could we visualize key milestones, say a count of how many of the key course readings a student has accessed each week so that the tutor can easily scan the students’ progress? It would look a bit like this:
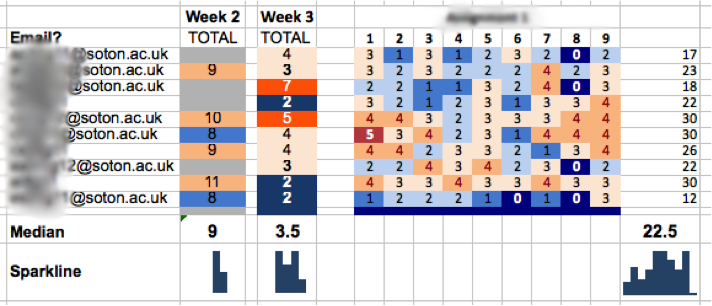
At a glance, the tutor can identify non progressing students, she should then be able to drill down for more data (e.g. how much an individual student has been posting in forums) and intervene with the students in whatever way they think best.
The problem becomes one of deciding what key measures should be used (you could even make it customizable at the tutor level so THEY choose the key measures) and how to visualize it successfully. I haven’t seen any VLE learning analytics dashboard that is up to the job IMHO (although I haven’t done a proper search). When compared to big data LA I think this ‘little data’ approach is:
– more achievable,
– has less ethical implications and
– neatly side steps the algorithm transparency problem: its the tutor’s expertise that is being used and that’s been going since teaching was introduced.
The screenshot comes from a prototype system I built to help track progress on a flipped learning course I used to deliver at Southampton Uni, I found that telling the students I was tracking their progress proved an excellent motivator for them to keep up with the out of class activities. Little data and flipped learning was the topic of a talk I did in 2014 at Southampton Uni.
I am responsible for a set of online tutorials (video and audio) and I’ve found Skype unsatisfactory, problems include:
I’ve done some research and hangouts seems to work well on all the common browsers and mobile devices. My Geo-Google colleagues all swear by it and its also more intuitive which is a common characteristic of Google software IMHO.
So we’re piloting a tutorial using Hangouts. I’ve prepared some notes for students to run through prior to coming on the call which I thought might be useful for someone thinking of trying out hangouts instead of Skype.
ELESIG = elearning evaluation special interest group.
I’ve just been to this meeting at the Royal Veternary college in Camden, London. The talks were interesting and there was some interesting discussion.
Problems engaging staff and students with Learning Analytics: It generally seemed as if Learning Technologists as a group are interested in what I call ‘small data’ i.e. Real time Learning Analytics for tutors and students as opposed to ‘Big data’ which tends to be of interest to management and is often not real time. However, not many people have projects producing results that can be discussed. There are barriers to the use of small data from :
Office Mix: I was surprised to find that my implementation of Office Mix (earlier post on Recording a presentation using PowerPoint Mix and see ‘training‘ for details of my teaching on use of Office Mix) as a way of introducing small data to students in the flipped MSc I’m supporting was actually advanced to where a lot of other people were. As I said to the group, the analytics of Office Mix promises much but I have yet to see it in action.
Michelle Milner of UEL: Michelle presented work that UEL has been doing around producing dashboards showing little data to students and tutors. She also explained how they had been using Kontext to track students’ use of Ebooks. One interesting fact she said was that they had done focus groups with students and that by discussing learning analytics students got more interested in the topic! To me this suggests a point made on a JISC podcast about learning analytics I heard recently: reports need to be delivered by a tutor as part of a one on one discussion if at all possible. Michelle noted that in the real world that’s a big ask for a tutor already pushed for time.
Andy Kons: Presented about an excel based program he’d produced to show analytics from Moodle.
“Don’t let anyone tell you certain types of data are not available in Moodle…. it’ll be there somewhere” says @AndyKons at #elesig
— Rose Heaney (@romieh) July 7, 2016
I went to some of the training sessions on accessibility run by JISC organised by University of Hertfordshire on 8/6/16. I thought I’d write up some notes to share.
Universities have a duty of care to ‘make all reasonable accommodations’ to our teaching and teaching materials to make them accessible. It is advisable to be anticipatory about this, if an organisation has a paper trail of embedding accessibility that creates a better defence in case we are taken to court and have done nothing. Different Universities have done more or less, in general, the more effort made the lower the risks are. Risks are low but the impact of them is potentially high especially to our reputation.
There are a range of users of teaching materials, some are disabled but don’t want to admit it, some are on a scale that means they could benefit from accessibility but who wouldn’t explicitly ask for it. Most students will avoid using usability tools if they can avoid it – they don’t like being seen as different.
There are a range of easy actions that could increase accessibility of materials with low cost in terms of time and culture change. A lot of these include good pedagogic practice anyway and can give rise to productivity benefits to all students. Examples:
There are a number of things that could be offered to students in induction e.g.:
Producing text versions of video and audio content is benefitial but clearly involves a big investment of time. Ebooks vary widely in their accessibility for students, PDF based images of text are impossible for screen readers to scan. What format are our ebooks in and what can we do about it if they aren’t in an accessible format?
A number of aspects of accessibility struck me. Inviting tutors to accessibility training is liable to be unpopular, why would they want to solve a problem they didn’t know they had? Better if we drip bits of accessibility into other training and support given to tutors.
The big take away that occurred to me is the link between flipped learning and accessibility. Students with common issues such as dyslexia, blindness and mental issues are all helped if they can access text versions of materials that that form the backbone of the course rather than have to learn by being sat in lectures. Flipped learning can help them by providing the out of class work in text form which can then be read by screen readers or read at students speed rather than listened to at ‘lecture delivery speed’. The class sessions of flipped learning are flexible so it also allows tutors to accomodate students needing more support.
Flipped learning often uses video, to be truly accessible, text versions of these need to be produced. A quick and dirty way of doing this is by uploading to YouTube, you can enhance the experience further by use of synote which allows a transcript to be synced with the video.
Intro: So I’ve been busy writing papers recently and, after a lot of experimenting, I’ve come up with a workflow which I like using mind maps to collate the literature and plan the paper’s structure. It would probably work well for other spatial thinkers so I thought I’d write it out:
1] Work out the topic area you want to write about. Start gathering relevant papers as PDFs.
2] For each paper, go through it highlighting the relevant parts to the paper you’re thinking of writing (I use Acrobat Pro).
3] Create a mind map, Xmind free version is the one I use. For each paper, create a new node on the left* side of the mind map. Branching out from the node, summarise the paper relevant to your planned paper in a series of points.
4] When you’ve got a fair few papers noted in this way, start planning the structure of the paper on the right side of the mind map. Each major section, (introduction, conclusion, methods etc.) gets a node of its own.
5] Branching out from each of the section nodes, write notes on what you will write. Don’t write actual text at this point.
6] Now start populating the right hand side with references from the left hand side. This will drive you to rewrite the detail on the right hand side.
7] Now iterate adding new papers as needed, incorporating them in the paper structure on the right and editing the paper structure.
8] When you’re mostly happy with the structure run through all the papers one by one reviewing their relevance and seeing where they could be fitted on the right where they haven’t already been added.
9] Now repeat but run through the structure on the right hand side reviewing every branch. You should be moving structure nodes around in the structure, deleting them or adding detail as necessary.
10] The paper writing is now just a matter of execution, write it starting at the introduction using the structure on the mind map as a guide. The abstract should wait until last.
Structure first: The advantage of this is that it encourages you to fix the large scale structure of the paper before getting into the actual sentences that make up the paper. If you can decide a node is not needed and delete it in the mind map then you’ve saved yourself the work of writing it out in full and then having to delete it.
Map of your paper: I also like the process of panning around a mind map editing things, it appeals to me to work spatially in this way rather than the more ‘linear’ scrolling up and down a long document.
Short study times on the train: A final advantage was that I used iAnnotate to highlight papers (step 2) on my iPad writing notes on apple notes. This can be done on a short journey such as a half an hour train trip. I’d later import the notes into the mind map.
*or the right, if you prefer. You’d just switch the structure over to the left as well.